La carrera por la Inteligencia Artificial (IA) ha dejado de ser una ventaja competitiva para convertirse en un imperativo de supervivencia en sectores altamente regulados. Sin embargo, mientras los CTO y los responsables de calidad visualizan un futuro de predicciones automatizadas y operaciones autónomas, un obstáculo silencioso pero crítico amenaza estas inversiones: la data quality (calidad de los datos) para la IA.
En mercados donde un error no es solo un fallo técnico, sino un riesgo de incumplimiento y sanción, la IA es tan fiable como los datos que la alimentan. Por ello, implementar algoritmos avanzados sobre una base de datos inconsistente es la forma más rápida de convertir la innovación en un riesgo operativo.
Sigue leyendo y descubre por qué la data quality es el requisito no negociable para cualquier iniciativa de Inteligencia Artificial exitosa y cómo estructurar la gobernanza de la IA para garantizar integridad y compliance.

¿Qué es la data quality?
En el entorno corporativo, la data quality no se limita únicamente a contar con “datos limpios”. El concepto también contempla la adecuación de los datos a su propósito (fit for purpose). Es decir, ¿el dato es lo suficientemente preciso, completo y fiable como para respaldar decisiones críticas y auditorías?
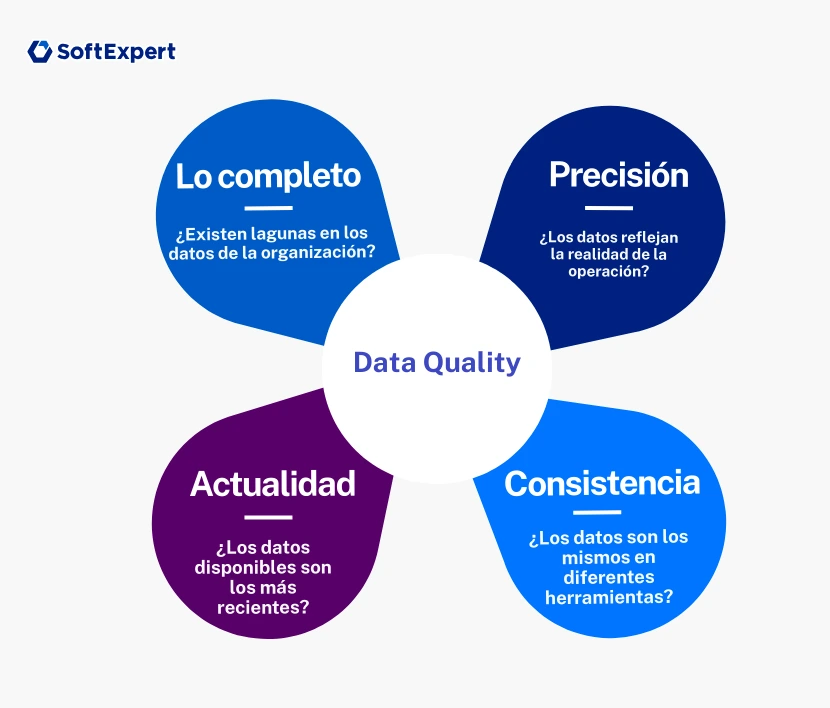
Para los responsables de compliance y calidad, la calidad de los datos debe evaluarse sobre pilares fundamentales, a menudo referenciados por metodologías como DAMA-DMBOK:
- Precisión: ¿el dato refleja la realidad del entorno productivo o del laboratorio?
- Integridad: ¿existen lagunas o valores nulos en campos obligatorios de los formularios de seguridad?
- Consistencia: ¿el código del producto es el mismo en el ERP, en el sistema de gestión de la calidad (QMS), en la plataforma de riesgos y en el resto de las herramientas?
- Actualidad: ¿la información disponible para la IA es la versión más reciente o ya se trata de un dato obsoleto?
Ignorar estos pilares sale caro. Según la consultora Gartner, la mala calidad de los datos puede costar a las organizaciones una media de 12,9 millones de dólares al año. Además, estudios del MIT Sloan Management Review indican que el coste de los “bad data” puede representar entre el 15% y el 25% de los ingresos de una empresa, un desperdicio inaceptable en mercados con márgenes de beneficio ajustados.

¿Cuál es la relación entre la data quality y la IA?
La Inteligencia Artificial, especialmente el Machine Learning (ML), no “sabe” nada por sí misma; identifica patrones estadísticos en grandes volúmenes de información. Por tanto, la relación es de dependencia directa: el dato es el insumo del algoritmo.
Así, si por ejemplo la base histórica de no conformidades utilizada para entrenar un modelo predictivo contiene errores de clasificación o descripciones ambiguas, la IA “aprenderá” el error. Este fenómeno se conoce como GIGO (Garbage In, Garbage Out): cuando se utiliza información deficiente, la tecnología genera resultados deficientes.
En el contexto actual de las IAs Generativas (LLM), el principal riesgo de una baja data quality es la “alucinación”. Cuando se alimenta con datos corporativos fragmentados o contradictorios, una LLM puede generar informes de auditoría plausibles, pero factualmente incorrectos.
Es decir, la Inteligencia Artificial inventa una información y la presenta como si fuera real. Esto expone a la empresa a riesgos graves frente a organismos reguladores como ANVISA, FDA o ISO y puede afectar de forma significativa a la operación de la compañía.

¿Por qué la IA no funciona sin data quality?
La falta de integridad de los datos genera fallos que, en muchos casos, solo se detectan cuando el daño ya se ha producido. Algunos de los principales problemas que surgen al utilizar IA sin data quality son:
- Sesgo algorítmico y operativo: los datos desbalanceados pueden sesgar la Inteligencia Artificial. Por ejemplo, si una línea de producción no registra microparadas en el sistema, la IA de mantenimiento predictivo asumirá que la máquina funciona a la perfección y no logrará anticipar una avería real.
- Pérdida de confianza: la adopción de nuevas tecnologías depende de la confianza del usuario. Si una IA sugiere una acción correctiva (CAPA) basada en datos deficientes y el responsable detecta el error, la confianza en la herramienta se rompe y la inversión tecnológica pierde su valor.
- Ineficiencia del equipo de datos: según IBM, los científicos de datos dedican alrededor del 80% de su tiempo a preparar y limpiar datos, y solo el 20% a la analítica y la modelización reales. Sin data quality desde el origen, los especialistas más costosos se convierten en simples “guardianes de datos”.
Los impactos negativos de la falta de data quality para la IA
La mala calidad de los datos tiene un efecto directo en procesos críticos. La ausencia de data quality, especialmente en iniciativas de Inteligencia Artificial, puede afectar a la operación de una empresa de múltiples formas, por ejemplo:
- Gestión de CAPA: una IA que analiza causas raíz a partir de datos de incidentes mal categorizados conducirá a planes de acción ineficaces, lo que provocará la repetición de la causa raíz.
- Documentos controlados: los metadatos incorrectos dificultan la recuperación de la información y comprometen la trazabilidad. En estos casos, una IA de búsqueda que entregue a un operario un documento obsoleto puede provocar accidentes laborales o desviaciones de calidad.
- Auditorías internas: los algoritmos que realizan preauditorías dependen de registros precisos. Los fallos en la calidad de estos logs pueden generar una falsa sensación de seguridad y dar lugar a “sorpresas” desagradables durante la auditoría externa oficial.
Cómo crear estructuras de gobernanza para garantizar la data quality
Para mitigar estos riesgos, la calidad de los datos debe dejar de ser una responsabilidad exclusiva de TI y convertirse en una estrategia de negocio. Llevar esta metodología a la práctica requiere los siguientes pasos:
- Define data stewards (guardianes de datos): nombra responsables en cada departamento (como Calidad, Ingeniería o RR. HH.) que asuman la integridad de los datos.
- Elimina los silos de datos: la fragmentación es enemiga de la data quality para la IA. Por ello, utiliza plataformas integradas que centralicen documentos, procesos y riesgos. Por ejemplo, con SoftExpert Suite unificas la gestión de calidad y cumplimiento para evitar la duplicidad de datos, que a su vez genera inconsistencias.
- Establece políticas de entrada de datos: la estandarización comienza en la recogida de la información. Crea máscaras de entrada y validaciones en formularios para impedir que el error humano contamine la base de datos.
La importancia del monitoreo continuo para la data quality de la IA
Los datos sufren entropía, es decir, tienden a degradarse con el tiempo a medida que cambian los procesos y se actualizan los sistemas. Por ello, es fundamental contar con un monitoreo continuo de la información. De este modo, es posible implementar reglas de calidad automatizadas.
Entre las estrategias de mejora continua, incluye dashboards de salud de datos y, además, alertas automáticas que informen a los responsables sobre anomalías en tiempo real. Presta atención a métricas como aumentos repentinos en campos “no completados” o valores fuera de la desviación estándar aceptable, por ejemplo.
Para facilitar la actualización y el seguimiento de la data quality, utiliza herramientas de observabilidad de datos. Son esenciales para garantizar que la IA siga consumiendo información fiable a lo largo de su ciclo de vida y, así, evitar la aparición de alucinaciones.
Trazabilidad y versionado: el secreto de la data quality de la IA con cumplimiento normativo
En sectores regulados, saber “qué” decidió la Inteligencia Artificial no es suficiente; es imprescindible saber “por qué” y “en base a qué”. La trazabilidad y la linaje de datos (data lineage) permiten responder a preguntas críticas de los auditores, como “¿Qué versión del procedimiento operativo estándar (POE) utilizó la IA para recomendar esta acción concreta?”.
Sin embargo, implementar mecanismos que garanticen la trazabilidad de extremo a extremo es un gran desafío. Para evitarlo en tu operación, es clave contar con sistemas de gestión robustos.
SoftExpert Document, por ejemplo, garantiza un versionado riguroso y la trazabilidad de auditoría de los documentos. Esto asegura que, incluso años después, la empresa pueda recuperar exactamente el snapshot de los datos utilizados en el momento de la decisión, respaldando su defensa en litigios o auditorías.

Lee más artículos como este:
- Conoce la gobernanza de IA y las tendencias futuras del área
- Gobernanza de Datos de IA para Ejecutivos: Qué papel juega la alta dirección en la adopción responsable de tecnologías emergentes
- Riesgos de la IA: cómo unir gobernanza, cumplimiento y seguridad en mercados regulados
Conclusión
La Inteligencia Artificial es un multiplicador de fuerza. Cuando se aplica sobre procesos y datos excelentes, escala la excelencia. Pero cuando se aplica sobre datos deficientes, escala el error y el riesgo.
Por ello, para las organizaciones en mercados regulados, la data quality no es un detalle técnico, sino el pilar de la conformidad y de la innovación sostenible. Antes de avanzar hacia algoritmos complejos, asegúrate de que tu fuente de datos esté en orden.
¿Buscas más eficiencia y conformidad en tus operaciones? Nuestros especialistas pueden ayudarte a identificar las mejores estrategias para tu empresa con las soluciones de SoftExpert. ¡Habla con nosotros hoy mismo!!




