La course à l’Intelligence Artificielle (IA) n’est plus un avantage concurrentiel, mais un impératif de survie dans les secteurs fortement réglementés. Pourtant, alors que les CTO et les responsables qualité envisagent un avenir fondé sur des prédictions automatisées et des opérations autonomes, un obstacle discret mais critique menace ces investissements: la qualité des données pour l’IA.
Dans des environnements où une erreur ne représente pas seulement une défaillance technique, mais un risque de non-conformité et de sanction, l’IA n’est fiable que dans la mesure où les données qui l’alimentent le sont. Mettre en œuvre des algorithmes avancés sur une base de données incohérente est donc le moyen le plus rapide de transformer l’innovation en risque opérationnel.
Poursuivez votre lecture et découvrez pourquoi la qualité des données est une condition non négociable pour toute initiative d’Intelligence Artificielle réussie, ainsi que la manière de structurer une gouvernance de l’IA garantissant l’intégrité et la conformité.

Qu’est-ce que la qualité des données?
Dans le contexte des entreprises, la qualité des données ne se limite pas à des « données propres ». Elle prend également en compte leur adéquation à l’usage prévu, autrement dit leur caractère fit-for-purpose. La donnée est-elle suffisamment précise, complète et fiable pour soutenir des décisions critiques et des audits?
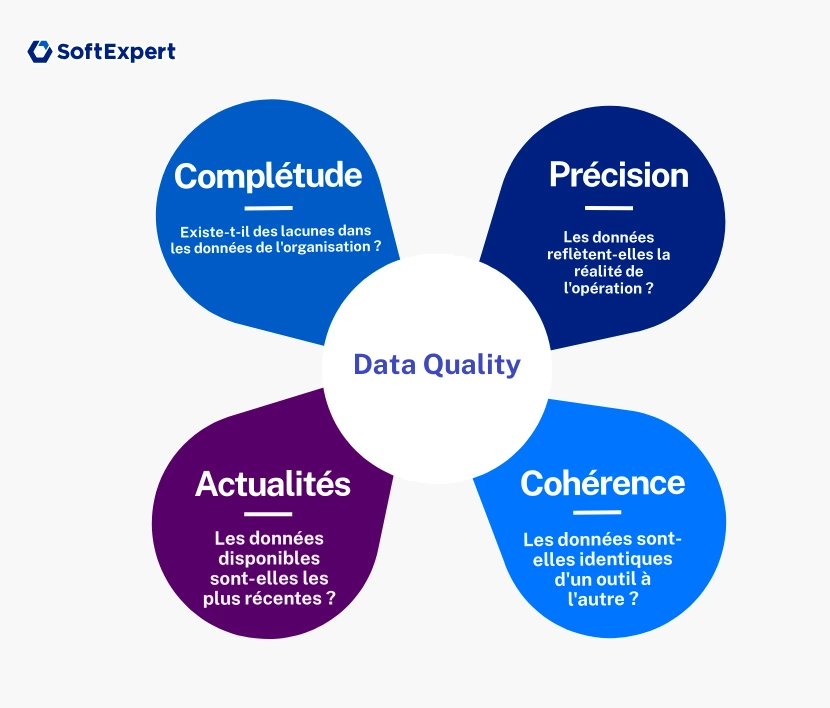
Pour les responsables conformité et qualité, la qualité des données doit être évaluée selon des piliers fondamentaux, souvent référencés par des cadres méthodologiques tels que le DAMA-DMBOK:
- Précision: la donnée reflète-t-elle fidèlement la réalité de l’atelier de production ou du laboratoire?
- Exhaustivité: existe-t-il des lacunes ou des valeurs nulles dans des champs obligatoires de formulaires de sécurité?
- Cohérence: le code produit est-il identique dans l’ERP, le système de management de la qualité (QMS), la plateforme de gestion des risques et les autres outils?
- Actualité: l’information mise à disposition de l’IA correspond-elle à la version la plus récente ou s’agit-il déjà d’une donnée obsolète?
Ignorer ces piliers a un coût élevé. Selon le cabinet Gartner, la mauvaise qualité des données peut coûter aux organisations en moyenne 12,9 millions de dollars par an. De plus, des études du MIT Sloan Management Review indiquent que le coût des « bad data » peut représenter entre 15% et 25% du chiffre d’affaires d’une entreprise, un gaspillage inacceptable dans des marchés aux marges bénéficiaires réduites.

Quel est le lien entre la qualité des données et l’IA?
L’Intelligence Artificielle, en particulier le Machine Learning (ML), ne « sait » rien par elle-même. Elle identifie des modèles statistiques à partir de grands volumes d’informations. La relation est donc de dépendance directe: la donnée est la matière première de l’algorithme.
Ainsi, si, par exemple, l’historique des non-conformités utilisé pour entraîner un modèle prédictif contient des erreurs de classification ou des descriptions ambiguës, l’IA apprendra ces erreurs. Ce phénomène est connu sous le nom de GIGO (Garbage In, Garbage Out): lorsque l’on fournit une information de mauvaise qualité, la technologie produit un résultat de mauvaise qualité.
Dans le contexte actuel des IA génératives (LLM), le principal risque lié à une faible qualité des données est l’« hallucination ». Alimentée par des données d’entreprise fragmentées ou contradictoires, une LLM peut générer des rapports d’audit plausibles, mais factuellement inexacts.
Autrement dit, l’Intelligence Artificielle invente une information et la présente comme si elle était réelle. Cela expose l’entreprise à des risques majeurs vis-à-vis des organismes de réglementation tels que l’ANVISA, la FDA ou l’ISO, et peut avoir un impact sérieux sur ses opérations.

Pourquoi l’IA ne fonctionne-t-elle pas sans une qualité des données adéquate?
Le manque d’intégrité des données entraîne des défaillances qui ne sont souvent détectées qu’une fois le dommage déjà causé. Parmi les principaux problèmes liés à l’utilisation de l’IA sans une qualité des données suffisante, on peut citer:
- Biais algorithmiques et opérationnels: des données déséquilibrées peuvent biaiser l’Intelligence Artificielle. Par exemple, si une ligne de production ne consigne pas correctement les micro-arrêts dans le système, l’IA de maintenance prédictive supposera que la machine fonctionne parfaitement et ne parviendra pas à anticiper une panne réelle.
- Perte de confiance: l’adoption de nouvelles technologies repose sur la confiance des utilisateurs. Si une IA recommande une action corrective (CAPA) sur la base de données de mauvaise qualité et que le gestionnaire identifie l’erreur, la confiance dans l’outil est compromise, rendant l’investissement technologique inefficace.
- Inefficacité des équipes data: selon IBM, les data scientists consacrent environ 80% de leur temps à la préparation et au nettoyage des données, ne laissant que 20% pour l’analyse et la modélisation proprement dites. Sans qualité des données dès la source, les experts les plus qualifiés deviennent de simples « gardiens de données ».
Les impacts négatifs d’une faible qualité des données pour l’IA
Une mauvaise qualité des données se répercute fortement sur des processus critiques. L’absence de data quality, en particulier dans les initiatives d’Intelligence Artificielle, peut affecter les opérations d’une entreprise de multiples façons, notamment:
- Gestion des CAPA: une IA qui analyse les causes racines à partir de données d’incidents mal catégorisées conduira à des plans d’action inefficaces, favorisant la réapparition de la cause racine.
- Documents contrôlés: des métadonnées incorrectes compliquent la récupération de l’information et nuisent à la traçabilité. Dans ces cas, une IA de recherche qui fournit un document obsolète à un opérateur peut, par exemple, provoquer des accidents du travail ou des écarts de qualité.
- Audits internes: les algorithmes utilisés pour réaliser des pré-audits reposent sur des journaux précis. Des lacunes dans la qualité de ces logs peuvent créer un faux sentiment de sécurité et entraîner de mauvaises surprises lors d’un audit externe officiel.
Comment créer des structures de gouvernance pour garantir la qualité des données
Pour atténuer ces risques, la qualité des données doit cesser d’être une responsabilité exclusivement informatique et devenir une véritable stratégie métier. La mise en œuvre de cette approche passe par les étapes suivantes:
- Définir des data stewards (gardiens des données): désignez des responsables dans chaque département, comme la Qualité, l’Ingénierie ou les Ressources humaines, chargés de garantir l’intégrité des données.
- Éliminer les silos de données: la fragmentation est l’ennemie de la qualité des données pour l’IA. Il est donc essentiel d’utiliser des plateformes intégrées qui centralisent documents, processus et risques. Avec le SoftExpert Suite, par exemple, vous unifiez la gestion de la qualité et de la conformité afin d’éviter la duplication des données, source d’incohérences.
- Établir des politiques de saisie des données: la standardisation commence dès la collecte des informations. Mettez en place des masques de saisie et des validations dans les formulaires pour éviter que les erreurs humaines ne contaminent la base de données.
L’importance du suivi continu pour la qualité des données de l’IA
Les données sont soumises à l’entropie, c’est-à-dire qu’elles ont tendance à se dégrader au fil du temps, à mesure que les processus évoluent et que les systèmes sont mis à jour. C’est pourquoi un suivi continu des informations est indispensable. Il permet notamment de mettre en place des règles de qualité automatisées.
Parmi les stratégies d’amélioration continue, intégrez des tableaux de bord dédiés à la santé des données, ainsi que des alertes automatiques informant les gestionnaires des anomalies en temps réel. Surveillez, par exemple, des indicateurs tels qu’une augmentation soudaine des champs non renseignés ou des valeurs en dehors des seuils acceptables.
Pour faciliter la mise à jour et le suivi de la qualité des données, utilisez des outils d’observabilité des données. Ils sont essentiels pour garantir que l’IA continue de s’appuyer sur des informations fiables tout au long de son cycle de vie et pour éviter l’apparition d’hallucinations.
Traçabilité et gestion des versions: le secret d’une qualité des données pour l’IA conforme aux exigences réglementaires
Dans les secteurs réglementés, savoir ce que l’Intelligence Artificielle a décidé ne suffit pas. Il est essentiel de comprendre pourquoi et sur quelles bases cette décision a été prise. La traçabilité et la lignée des données (data lineage) permettent précisément de répondre aux questions clés des auditeurs, telles que: «Quelle version de la procédure opérationnelle standard (SOP) l’IA a-t-elle utilisée pour recommander cette action spécifique?».
Cependant, la mise en place de mécanismes garantissant une traçabilité de bout en bout représente un défi majeur. Pour éviter ce risque au sein de votre organisation, il est indispensable de s’appuyer sur des systèmes de gestion robustes.
SoftExpert Document, par exemple, assure un contrôle rigoureux des versions et une piste d’audit complète des documents. Cela permet à l’entreprise de retrouver, même plusieurs années plus tard, l’instantané exact des données utilisées au moment de la prise de décision, garantissant ainsi une défense solide lors de litiges ou d’audits.
Lire d’autres articles comme celui-ci :
- Comprendre la gouvernance de l’IA et les tendances futures du domaine
- Gouvernance des données de l’IA pour les cadres : quel rôle joue la direction dans l’adoption responsable des technologies émergentes
- Risques de l’IA : comment unir gouvernance, conformité et sécurité sur des marchés réglementés
Conclusion
L’Intelligence Artificielle est un puissant levier de performance. Appliquée à des processus et à des données de haute qualité, elle amplifie l’excellence. En revanche, lorsqu’elle repose sur des données médiocres, elle amplifie les erreurs et les risques.
Ainsi, pour les organisations évoluant dans des marchés réglementés, la qualité des données n’est pas un simple détail technique, mais le socle de la conformité et de l’innovation durable. Avant de déployer des algorithmes complexes, assurez-vous que vos sources de données sont fiables et maîtrisées.
Vous cherchez plus d’efficacité et de conformité dans vos opérations ? Nos spécialistes peuvent vous aider à identifier les meilleures stratégies pour votre entreprise avec les solutions de SoftExpert. Contactez-nous dès aujourd’hui !!




